AmadeuSYで音楽の一歩を踏み出そう
AmadeuSYは誰でも簡単にオリジナル音源を作れます。
作曲者も自分で音源を作って楽しみたい人も、もちろん研究者や技術者も全ての人が参加できます。
STRATEGIC PARTNER
AmadeuSYは誰でも簡単にオリジナル音源を作れます。
作曲者も自分で音源を作って楽しみたい人も、もちろん研究者や技術者も全ての人が参加できます。
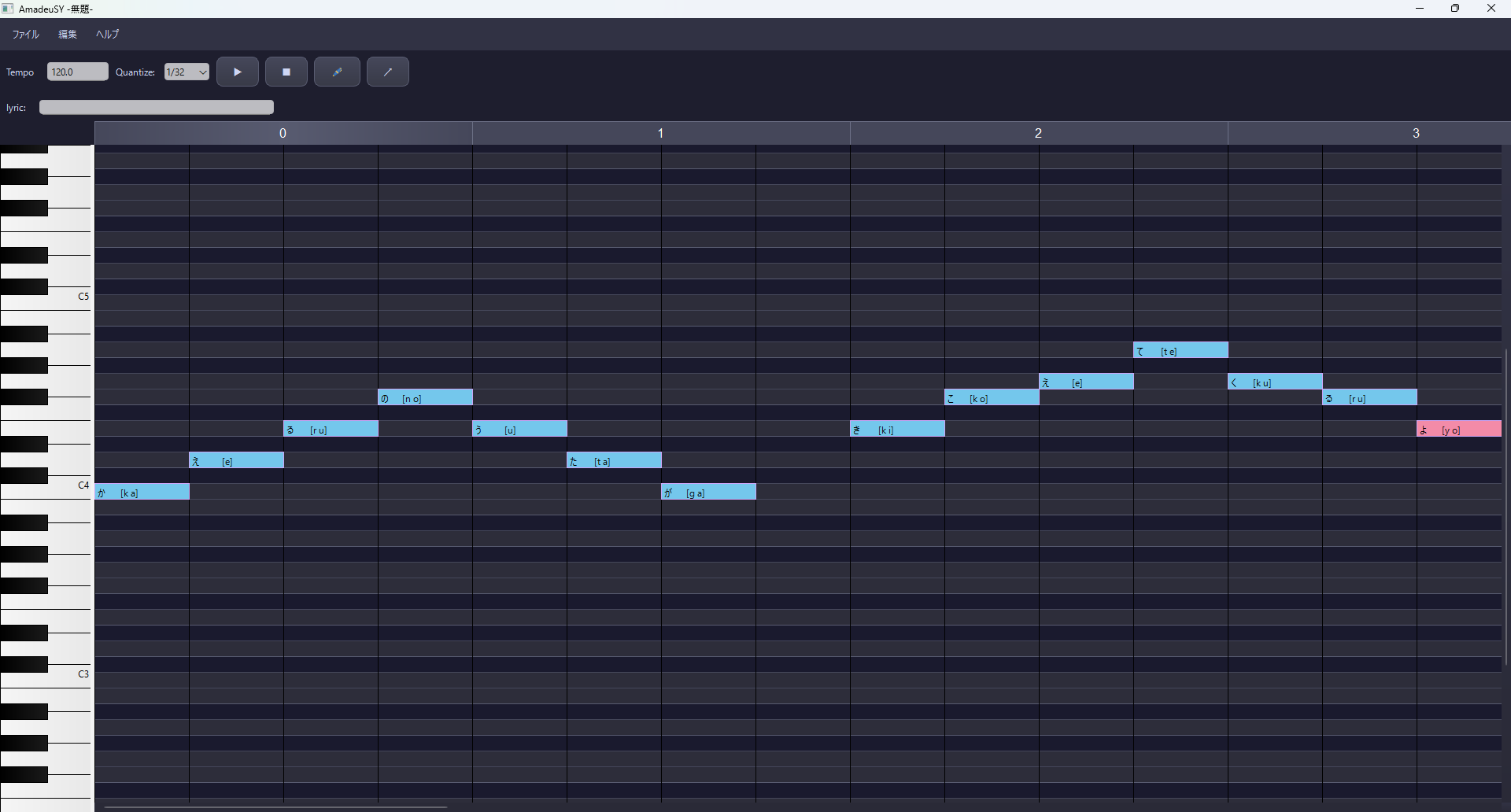
次世代AIエディタのプレビューをご覧ください
AmadeuSYは、2026年、
「ずんだもん大規模読唇データベース」を基盤とし、
デモ用の音声合成モデルを開発します
1つの歌声音声ファイルで歌唱テクニックを再現できます
ポップス、ロック、バラードなど、様々なジャンルに特化した個性豊かなAIシンガーたちが、あなたの楽曲を歌い上げます。
ピッチ、タイミング、ビブラートを細かく調整し、楽曲に最適なパフォーマンスを作り出せます。
SSS合同会社様主導の「ずんだもん大規模読唇データベース」の構築において、AmadeuSYのラベリングAIツールが採用されました。
最新の生成音声サンプル (YouTube)
AmadeuSY(旧称 "Voicing")は、人類とAIの共存を目標に立ち上げられたAI研究開発の総合ブランドです。 歌声合成から始まったこのプロジェクトは今や多方向へ展開し、お馴染みの音声合成、声質変換をはじめ、LLM、画像生成、動画生成、ロボット分野など幅広い分野での応用を目指しています。 AIをこれから先人類とともに技術革新を生み出していくパートナーであると位置づけ、人類とAIの共存を実現していくことを目指しています。
Cantsoftとの提携により、世界中のクリエイター、企業などと提携し人類の技術革新を促進していくことを目指しています。
AmadeuSYは、オープンな開発を目指すプロジェクトです。
エンジニア、デザイナー、投資家、そしてクリエイター。
全ての「同志」と共に、新しい音楽の未来を創り上げたいと考えています。